AI PDF Parser for structured data extraction

How to extract data from PDFs with AI
Create a repeatable PDF data extraction workflow in a few steps: describe the data you need, upload the document, then review and export structured output.
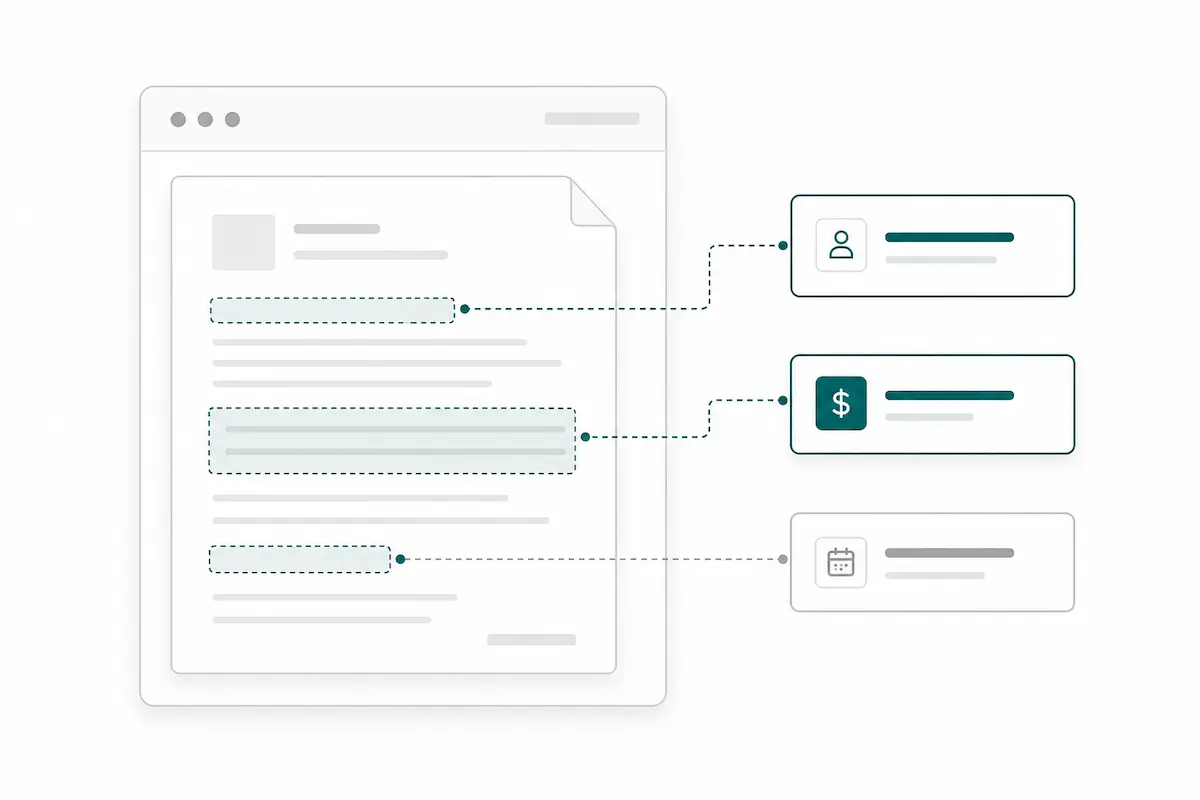
Define the fields you need
Choose what to capture, such as invoice totals, dates, names, addresses, bank statement rows, contract terms, or custom table columns. Your extraction schema keeps every result organized the same way.
Upload native or scanned PDFs
Add PDFs from your daily workflow, including invoices, receipts, purchase orders, reports, forms, and scans. The AI PDF parser reads the document and applies your extraction rules to each file.

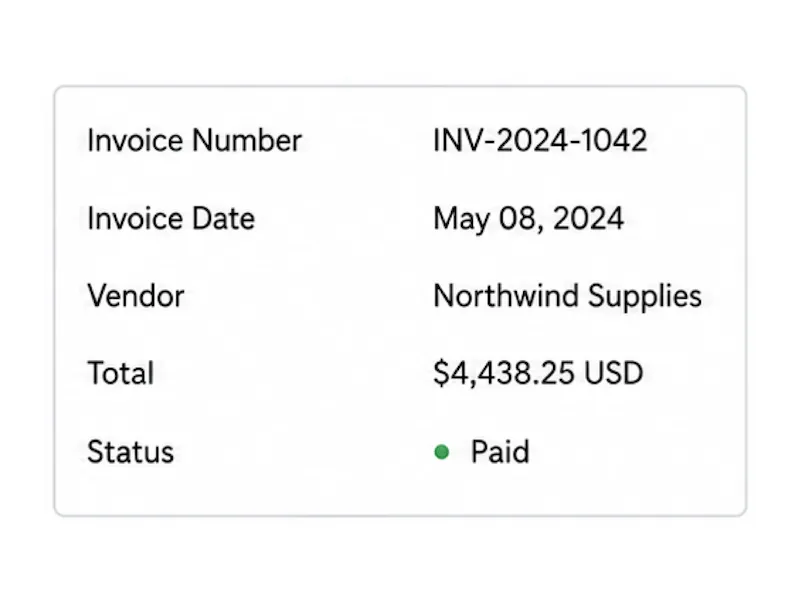
Review and download structured data
Check the extracted fields beside the original document, then download the result as JSON, CSV, or Excel for spreadsheets, databases, or downstream automation.
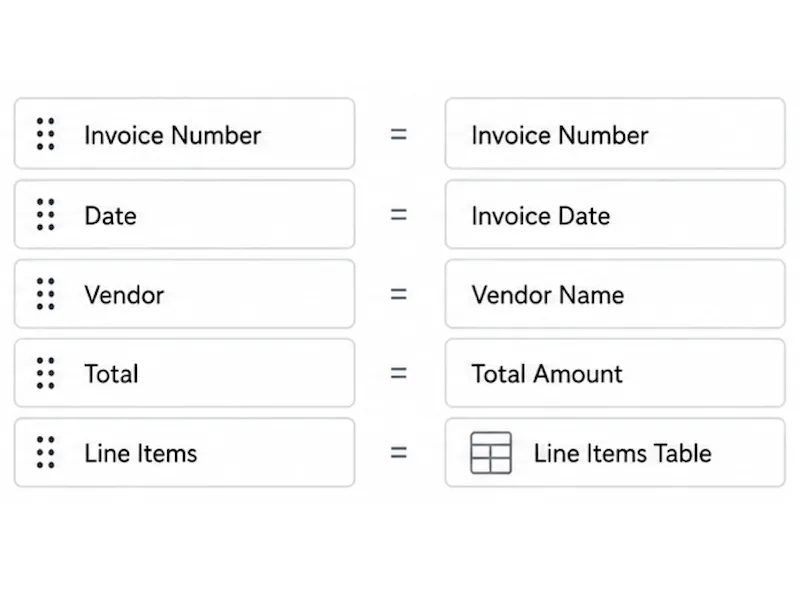
Create a custom PDF extraction schema—without code
Choose the fields you want—such as invoice numbers, dates, totals, addresses, contract terms, or any custom value. Vellparser's AI PDF parser organizes every result into the same structured format, giving your team usable data without manual copy and paste.
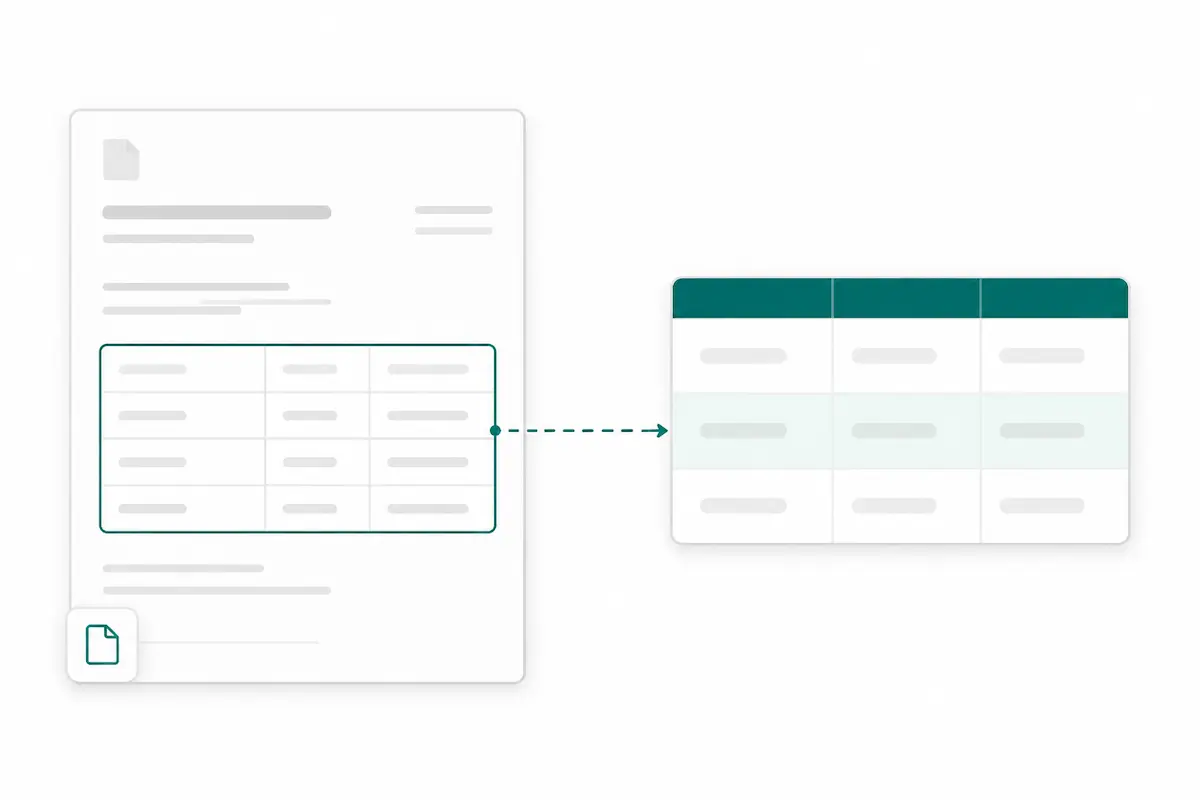
Extract PDF tables and line items without retyping
Turn invoice line items, purchase order details, bank statement transactions, and report tables into clean rows and columns. Export the extracted PDF data to JSON, CSV, or Excel instead of rebuilding every table by hand.

Parse native and scanned PDFs with AI
Process text-based PDFs, scanned documents, receipts, forms, statements, and images in one workflow. OCR and AI data extraction work together to turn readable scans into structured fields—not just a block of unorganized text.
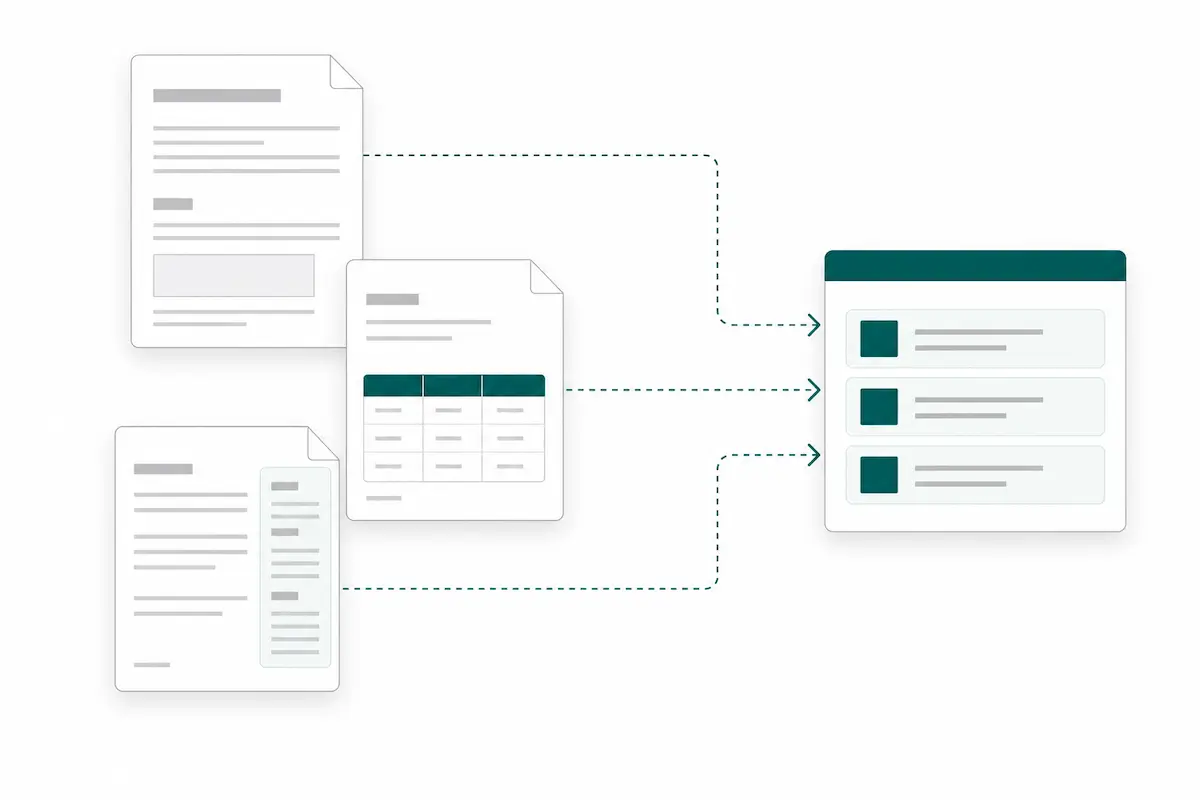
Keep extracting data when PDF layouts change
Supplier invoices, customer forms, and reports rarely share one fixed template. The AI parser uses labels, context, and document structure to find the fields you defined across different layouts, so you can reuse one extraction workflow for more files.

Review extracted PDF data before it moves downstream
Compare extracted fields with the original PDF, catch missing or unusual values, and confirm the result before export. Send cleaner data to spreadsheets, databases, and automated workflows while keeping a human in control of important documents.
A complete workflow for PDF data extraction
Turn native or scanned PDFs into structured data you can check, download, and use in spreadsheets, databases, or automated workflows.
Export PDF data to JSON, CSV, or Excel
Choose the format that fits your next step: JSON for apps and databases, or CSV and Excel for analysis, sharing, and spreadsheet workflows.
Turn PDF tables into structured rows
Capture invoice line items, bank transactions, order details, and report tables as reusable rows and columns—without copying each cell by hand.
Extract data from scanned PDFs with OCR
Read clear scans and image-based PDFs, then use AI to organize the recognized text into the fields and tables your workflow needs.
Reuse schemas across similar PDFs
Define the output once for invoices, statements, forms, or another document type, then apply the same structure to future files.
Review AI-extracted data before export
Compare results with the source PDF and correct missing or unusual values before they reach a spreadsheet, database, or automated process.
Keep PDFs and extracted data organized
Keep each source document with its extraction task and structured result, so your team can find, review, and download the right data later.
Frequently Asked Questions
An AI PDF parser reads a PDF, identifies the information you need, and returns it as structured data. Unlike a basic PDF-to-text converter, it can organize labels, values, tables, and line items into named fields that are ready to review or export.
OCR recognizes the text visible in a document. AI PDF parsing uses that text together with labels, layout, and context to determine what the information means and where it belongs—for example, separating an invoice number from a due date or turning line items into structured rows.
Yes. OCR and AI extraction can process readable scanned PDFs and image-based documents. Clear, correctly oriented scans produce better results; blurry, cropped, low-contrast, or heavily handwritten files may require additional review.
No. You define the fields and structure you want instead of drawing fixed zones on every page. The same extraction schema can be reused across similar documents even when suppliers, forms, or page layouts vary.
Yes. The AI parser can turn invoice line items, statement transactions, purchase order details, form entries, and report tables into structured rows. You can then review the result and export it to JSON, CSV, or Excel without rebuilding the table manually.
Yes. You can export extracted PDF data as JSON, CSV, or Excel. Use JSON for applications, APIs, or databases, and use CSV or Excel for spreadsheet review, analysis, and sharing.
Accuracy depends on the document quality, layout complexity, and fields being extracted. Clear files and well-defined schemas generally produce better results. You can compare extracted values with the original PDF so important data can be checked before export.
No. Your uploaded PDFs, extraction instructions, and extracted results are not used to train AI models. Your documents remain part of your private extraction workflow.
Start turning PDFs into structured data
Upload a PDF, define the fields you need, and extract tables, line items, and key details into JSON, CSV, or Excel.
